Git trabaja de una forma interesante para llevar un historial de los cambios en los archivos. Aunque pudiera parecer que busca los cambios en cada uno de estos lo que realmente hace es llevar un archivo llamado index, en el cual va insertando los cambios que van ocurriendo. De esta forma solo con leer el archivo index puede saber que archivos y que contenido dentro de los mismos ha sido cambiado.
Una vez que entendemos ese concepto de como Git lleva los cambios registrados, es cuando podemos empezar a sacar el verdadero provecho de la herramienta, ya que es en este momento cuando podremos empezar a utilizar los diferentes comandos para llevar los cambios de nuestro repositorio y manejarlos desde una perspectiva lógica.
Clasificación de archivos dentro de Git
Antes de continuar con puntos más profundos, debemos ver como Git clasifica sus archivos. Esto no significa una clasificación por tipo de archivo debido a su extensión, si no por el estado del mismo en relación a nuestro repositorio y su index.
Básicamente tenemos tres tipos de archivos en GIT, cada uno tiene su propio momento dentro del repositorio, veamos cuales son estos:
git add nombredelarchivo
Ejemplo práctico de la clasificación de archivos
Veamos ahora un pequeño ejemplo práctico de cómo podemos detectar los tipos de archivo en un repositorio Git, para ello debemos seguir los siguientes pasos:
1- Vamos a crear una carpeta nueva en nuestro equipo que se llame archivosGit.
2- Una vez creada la carpeta vamos a ingresar dentro de ella desde nuestra consola y ahí vamos a ejecutar el comando git init y luego hacemos git status para ver el estado de nuestro repositorio, veamos como luce la aplicación de los comandos anteriores:
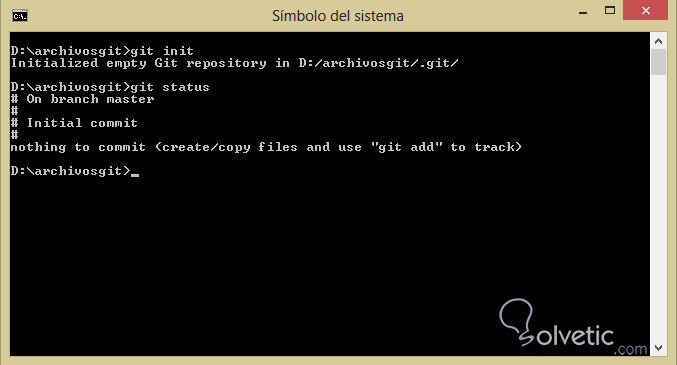
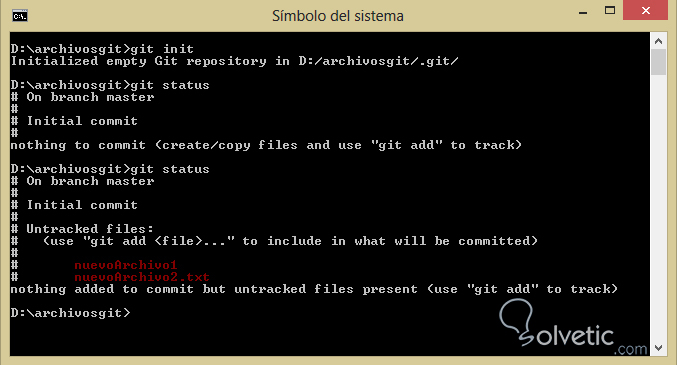
3- Cuando hayamos cumplido el paso anterior ya tendremos un repositorio Git inicializado y listo para trabajar, entonces podemos crear un nuevo archivo en esa carpeta y haremos nuevamente git status para ver el cambio, debemos tener nuestro nuevo archivo bajo la clasificación untracked.
4- Vamos a repetir el paso anterior y crearemos un nuevo archivo, si vemos el resultado de hacer nuevamente git status contaremos ambos archivos, veamos:
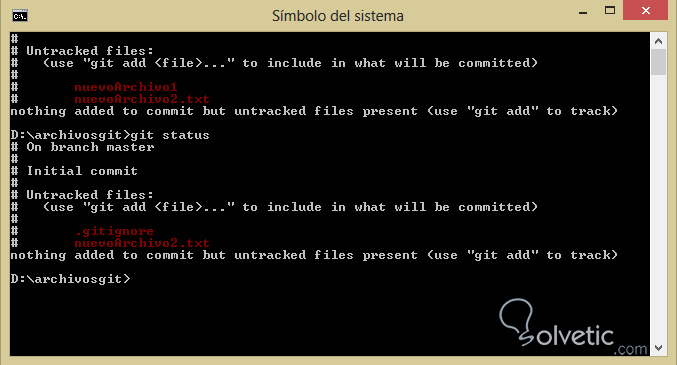
5- Ahora vamos a crear un nuevo archivo llamado .gitignore, nótese el punto antes del archivo y dentro vamos a colocar el nombre de uno de nuestros archivos anteriores, hacemos nuevamente git status y veremos que ahora solo nos sale el archivo que no está en él .gitignore y el archivo .gitignore que acabamos de crear:
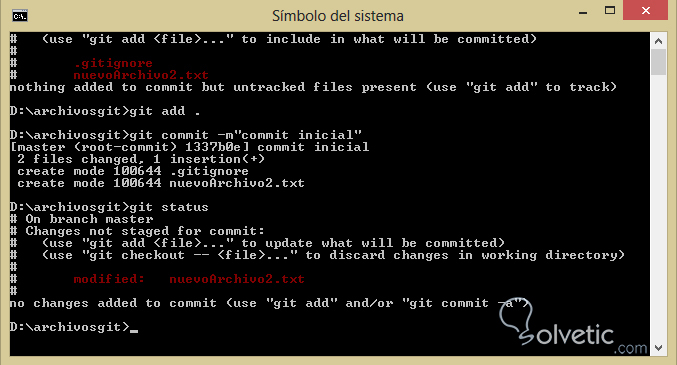
6- Luego haremos un git add . para así añadir todos nuestros archivos y finalmente ejecutaremos un git commit -m”commit inicial” con ello añadiendo nuestros archivos al repositorio, si hacemos un cambio en el archivo que no colocamos dentro del .gitignore y lo salvamos, si ejecutamos nuevamente git status veremos a un archivo en estado o clasificación tracked.
El comando git add
En el ejemplo anterior pudimos ver la utilización del git add y quizá podamos pensar que es un comando más de nuestra herramienta pero este es de suma importancia, es el que nos permite añadir un archivo a nuestro repositorio si aún no existe en él y también nos permite añadir los cambios que hayan sucedido en un archivo existente en nuestro repositorio.
Es muy importante que luego de hacer cualquier cambio en el repositorio añadamos los archivos con git add, ya que de lo contrario no podremos salvar nuestros cambios, además de estar creando diferentes versiones del archivo lo que nos puede llevar a un posible conflicto a futuro.
Utilización del git add
Dentro de nuestra carpeta archivosGit que hemos creado en el ejemplo anterior del tutorial, vamos a añadir un nuevo archivo que le colocaremos nuevoArchivo3 y luego en el archivo existente que no está en él .gitignore vamos a hacer un cambio.
Lo que queremos lograr con esto es poner a prueba la forma de utilizar nuestro comando git add, veamos como luce esto en nuestra consola de comandos:
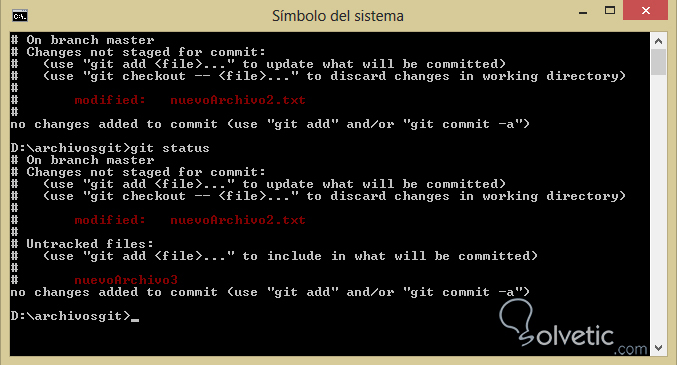
Al haber seguido las instrucciones anteriores debemos haber llegado a tener en pantalla algo como lo anterior, donde se nos muestra un archivo modificado y un archivo totalmente nuevo en el repositorio.
Ahora vamos a añadir el nuevo archivo al repositorio, pero no lo haremos con el archivo ya existente ni el que hemos modificado anteriormente. Para ello solo debemos hacer git add nombredenuestroarchivo. Acto seguido haremos git status. Veamos:
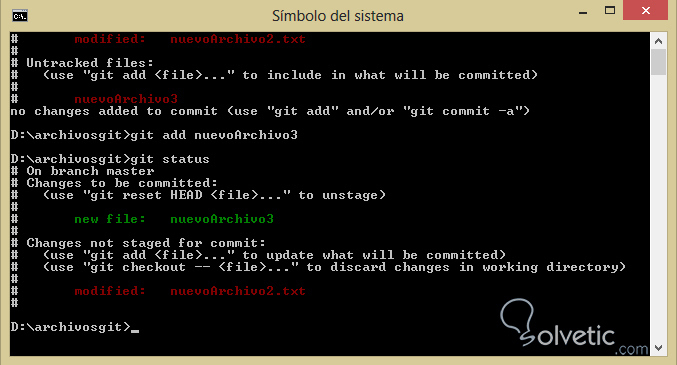
Como podemos notar ya nuestro repositorio toma en cuenta el archivo que hemos añadido con git add, esta es la manera en la que de forma básica podemos trabajar los cambios de nuestros archivos.
Eliminar archivos del repositorio
La siguiente acción que debemos saber realizar es eliminar los archivos de nuestro repositorio, ya que es muy común que hayamos creado algo por error o simplemente estemos poniendo en orden las cosas dentro del mismo.
Hay dos cosas a tomar en cuenta, podemos eliminar el archivo del index de nuestro repositorio pero mantener dicho archivo en el sistema de nuestra carpeta, por lo que si hacemos un git status lo volveremos a ver disponible. O si no podemos borrar el archivo tanto de nuestra carpeta como del index de nuestro repositorio, para ello podemos utilizar el comando git rm.
El comando git rm - -cached
Al utilizar el comando rm con la opción añadida de cached, lo que hacemos es borrar el archivo en cuestión del index, sin embargo lo mantendremos en nuestro equipo, este comando se utiliza mucho cuando no deseamos añadir aún dicho archivo a nuestro repositorio pero necesitamos salvar los otros cambios.
Para utilizarlo simplemente hacemos el comando cuando ya hayamos añadido con git add algún archivo, veamos como luce esto en nuestra consola de comandos:
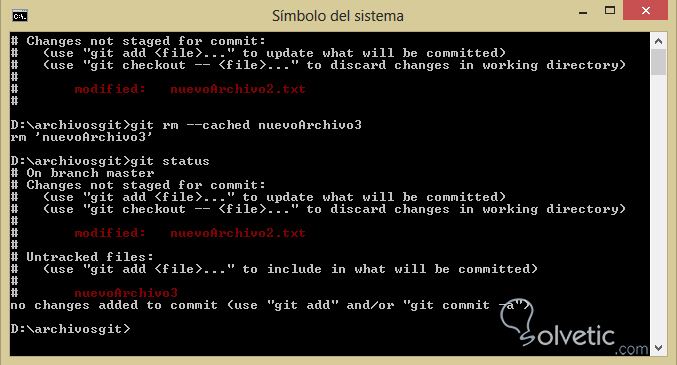
Notamos que el archivo nuevoArchivo3 que habíamos añadido a nuestro repositorio ahora no está y tiene la clasificación untracked.
El comando Git rm
Ahora veamos cómo utilizar el comando git rm, este comando es mucho más poderoso ya que elimina directamente al archivo del index y de la carpeta, es por ello que hay que ser cuidadosos en el momento en que decidamos utilizarlo en nuestro repositorio, es muy probable que una vez aplicado no podamos recuperar el cambio.
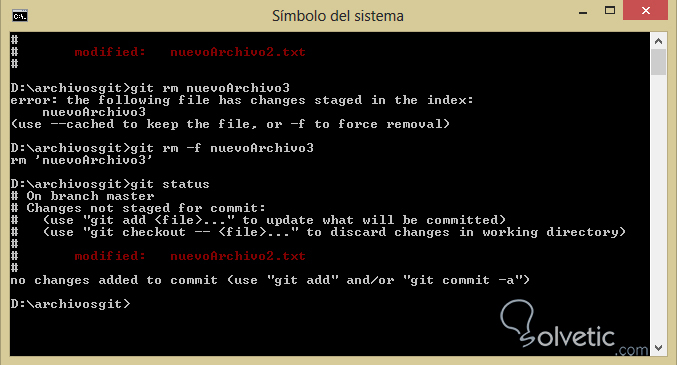
Veamos en el siguiente ejemplo como funciona cuando lo aplicamos sobre un archivo, en este caso vamos a volver a añadir nuevoArchivo3 con git add y luego aplicaremos sobre este git rm:
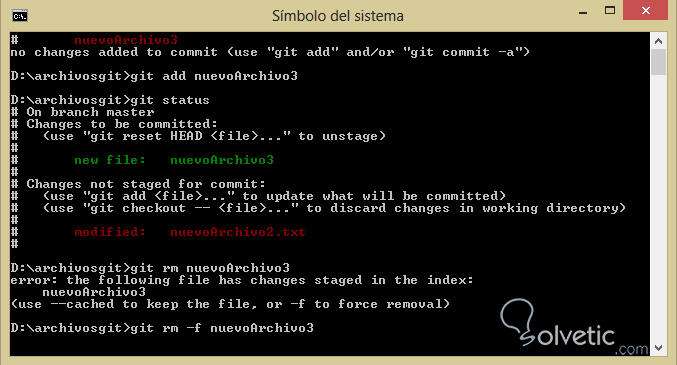
Vemos que cuando lo hacemos directamente git nos muestra un error y nos pide que hagamos un borrado forzado al añadir el parámetro -f a la instrucción esto es debido a lo importante del cambio, finalmente haremos un git status y notaremos que dicho archivo desapareció de nuestro repositorio en su totalidad.
Más del .gitignore
Pudimos ver que podemos añadir un archivo especifico a nuestro archivo .gitignore, sin embargo cuando trabajamos en un entorno en el que manejamos cientos o tal vez miles de archivos no sea muy práctico, es por ello que podemos utilizar patrones.
Un patrón nos va a permitir indicarle a Git que un archivo que cumpla la secuencia de caracteres o expresión debe ser ignorado, con ello podemos indicarle extensiones específicas, ya sea en todo el proyecto o dentro de una carpeta en especial. Veamos un ejemplo de esto.
*.jpg va a ignorar todos los archivos .jpg de nuestro proyecto, pero si queremos mantener la traza de uno en particular solo debemos añadir:
!nombrearchivo.jpgAsí de sencillo tenemos una estructura fuerte y compleja que nos permite mantener nuestro repositorio organizado.
Con esto finalizamos este tutorial, hemos visto de manera extensa la forma en la cual Git lleva o maneja los cambios en nuestros archivos, es importante dominar esta materia, ya que con ello podremos trabajar de forma más eficiente en entornos de equipo donde se maneje Git como controlador de versiones.

