
Dependiendo qué tan potente sea el equipamiento que disponemos y los recursos necesarios para nuestros sistemas, tendremos un ratio promedio de máquinas virtuales por servidor.
Pongamos por ejemplo el mantenimiento programado de un servidor en el Centro de Cómputos. Algunos años atrás si éste no era parte de un clúster, el sistema contenido en el equipo quedaría fuera de línea, por consecuente los usuarios también se verían afectados y/o el personal involucrado en el mantenimiento debía trabajar en ventanas de tiempo reducidas (por no decir incómodas).
En el caso de un ambiente virtualizado, las máquinas virtuales simplemente pueden “moverse o migrarse” a otro integrante de un clúster y es posible apagar el equipo para trabajar en él. Problema resuelto.
Comencemos a ver situaciones donde la falta de servicio no es programada.
Cada vez que creamos una máquina virtual es recomendable instalarle un compendio de aplicaciones y drivers que optimizan el comportamiento del hardware virtual en su totalidad (disponible para Windows, Mac OS, Linux y otros SO). Estas herramientas, llamadas VMTools, entre otras cosas incluyen la posibilidad de que el host realice un monitoreo de la máquina virtual (a través de heartbeats, como en los clúster). De no responder en un período determinado, reinicia su Sistema Operativo.
Un caso similar sucede con el monitoreo de aplicaciones, pero primero es necesario obtener el SDK apropiado (o estar usando una aplicación que soporte Monitoreo de Aplicaciones de VMware).
Pero... ¿qué sucede si la falla es de hardware?
El clúster anteriormente mencionado es la primera capa de la solución.
A grandes rasgos, estas tres tecnologías mitigan el tiempo en que nuestra información es inaccesible. Ahora, dependiendo del licenciamiento que tengamos, también podremos disponer de dos funcionalidades muy interesantes: Alta Disponibilidad (HA) y Tolerancia a Fallos (FT).
En ambos casos requerimos de un clúster con almacenamiento compartido. Sin necesidad de instalar software adicional, es posible habilitar y configurar HA de forma tal que ante la falla de un servidor o máquina virtual en el clúster automáticamente se iniciará en otro integrante del mismo. Vale aclarar que HA no está pensado para VMs (máquinas virtuales) de misión crítica. Así que el tiempo estimado sin servicio será: "Arranque del Sistema Operativo + Inicio de los servicios".
Tenemos X cantidad de máquinas virtuales distribuidas en Y servidores de un clúster.
¿Cuántos hosts pueden fallar sin afectar la disponibilidad y performance de nuestro entorno virtual?
Es posible configurar HA para que soporte una cantidad específica de fallos de servidores, asegurando que en la recuperación haya suficientes recursos restantes.
HA divide en porciones los recursos disponibles de un clúster teniendo en cuenta CPU y RAM configurada y consumida por nuestras máquinas virtuales de una forma muy conservativa. Toma la mayor reserva de CPU configurada de cualquier VM en cada host del clúster y luego la mayor reserva de memoria y su exceso. De no haber reserva configurada, tomará un mínimo de 32 Mhz por VM para CPU y 0 Mb de RAM + su exceso.
Con estos números asume que cada máquina virtual utiliza consumirá esa CPU y memoria, entonces genera un valor llamado tamaño de slot (slot size). Con este valor, se determina cuantos slots hay disponibles/utilizados por cada host.
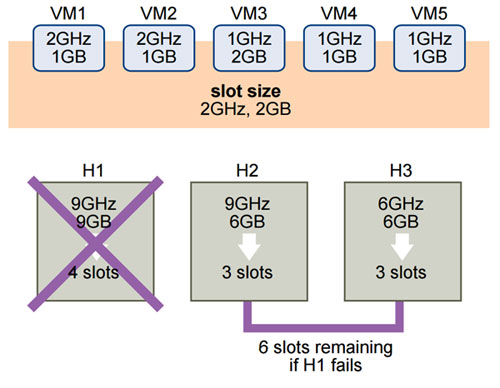
El problema se plantea cuando por ejemplo tenemos una sola máquina con una gran reserva de CPU y memoria. Al tomarse reservas configuradas, es muy probable que el resto de nuestras máquinas virtuales realmente no necesiten esos recursos, resultando en una menor cantidad de slots para nuestro clúster.
A diferencia de la opción anterior, esta va muy bien cuando se dispone de VMs con configuraciones de CPU y memoria altamente variables.
Es posible configurar valores porcentuales de CPU y memoria por separado, siendo de esta forma aún más flexible y por consecuente ahorra recursos. Por lo general, este es el método preferido para configurar HA.
Este es la típica configuración de clúster en espera. Principalmente se da esta opción ya que algunas organizaciones mantienen políticas que indican que debe haber servidores en espera ante cualquier desastre. Dado que VMware hace una buena administración de la tolerancia a fallas, tal vez esta sería la opción cuando los recursos abundan… pero definitivamente, no es la mejor.
La migración en vivo permite mover máquinas virtuales en funcionamiento de un servidor físico a otro manteniendo su conexión de red e identidad. Se transfiere la memoria activa (los procesos en ejecución) a través de la red de alta velocidad. Todo el proceso lleva menos de 5 segundos en una red de gigabit.
Es posible mover la VM, los archivos que ésta utiliza o ambos y el procedimiento se puede hacer con la máquina encendida o apagada. En este último caso, lo llamamos “migración en frío” y si la máquina se encuentra en ejecución, lo llamaremos vMotion.
- Reorganización de las VMs, optimizando de esta manera los recursos. Quitarlas de servidores con tendencias a fallas o saturados.
- Optimización automática de los recursos disponibles (trabajo en conjunto con Dynamic Resource Scheduler o DRS).
- Hacer mantenimiento de la infraestructura subyacente sin necesidad de programación de mantenimiento o interrupción del funcionamiento del negocio.
Cada uno de los componentes del estado de la VM se maneja de forma diferente durante la migración. La configuración general es lo más simple, no se mueve sino que se re-crea en el equipo destino.
Como el disco no puede ser re-creado en tan poco tiempo, es necesario disponer de almacenamiento compartido. El estado actual de la memoria se copia gradualmente hacia el host destino, al finalizar la copia se comparan las diferencias existentes que surgieron durante la migración, se congela el estado de la VM origen y activa el Sistema Operativo en la VM destino.
Debido a que en algunos casos la opción de reiniciar la máquina no es lo ideal, para misión crítica disponemos de la Tolerancia a Fallos (Fault Tolerance). Lo que se desea en estos casos que en ningún momento deje de funcionar, inclusive si su host falla. La única forma que hay para que esto sea posible es si la VM estuviera funcionando en dos lugares al mismo tiempo. Se configura a nivel de máquina virtual y generará una copia exacta de la VM, manteniéndola replicada en todo momento al 100% en otro servidor, por lo que ante una falla de hardware simplemente continuará funcionando su gemela sin pérdida de información alguna. Interesante ¿no?
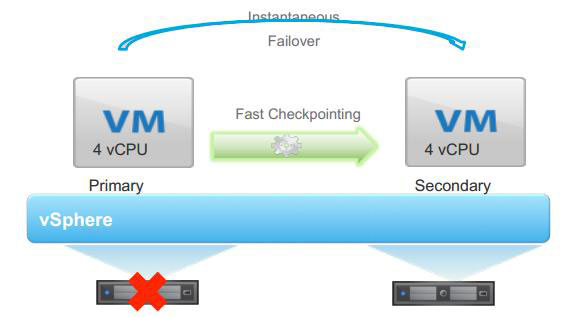
Si sólo de recursos se tratara, habilitaríamos FT en todas las máquinas virtuales de nuestro centro de cómputos, pero en versiones anteriores de vSphere nos encontrábamos con algunas limitaciones, la más importante: No era posible habilitar FT en máquinas que utilizaran más de un procesador virtual. Por suerte, en la última versión del producto, soporta hasta 4 procesadores virtuales simultáneamente por máquina protegida, de todas formas habrá que considerar el licenciamiento:
El número de vCPUs soportador por una VM con FT habilitado está limitado por el nivel de licenciamiento adquirido para vSphere.
Fault Tolerance es soportado de la siguiente manera:
- vSphere Standard y Enterprise. Permite hasta 2 vCPUs.
- vSphere Enterprise Plus. Permite hasta 4 vCPUs.
Ese no es el único requerimiento del sistema.
- No es posible tomar instantáneas (snapshots) de las VMs que estén siendo protegidas con FT y los mismos deben ser eliminados previo a la habilitación de esta función.
- Discos virtuales (VMDK) mayores a 2 Tb.
- Existe una lista de dispositivos y características específicas en la documentación de VMware.
Y también existe una limitación en la cantidad de VMs por servidor: un máximo de 4 máquinas protegidas por host u 8 vCPUs protegidos (al límite que se llegue primero). Estos máximos incluyen la máquina primaria y secundaria (y vCPUs)
Legacy FT = No soportado por las placas de red configuradas para FT logging FT = Soportado
Legacy FT = No soportado FT = Soportado
Legacy FT = EZT (Eager Zeroed Thick) FT = Todos los tipos, incluyendo thick y thin
Legacy FT = Copia única FT = La máquina Primaria y Secundaria mantienen copias independientes, esto permite almacenarlas en distintos datastores e incrementar la redundancia
Legacy FT = Se recomienda una 1-Gb NIC dedicada FT = Se recomienda una 10-Gb NIC dedicada
Legacy FT = Requiere el mismo modelo de CPU y familia. Versiones de vSphere casi idénticas FT = Los CPUs deben ser compatibles con vSphere vMotion o EVC. La versión de vSphere debe ser compatible con vSphere vMotion
Legacy FT = No siempre soportado FT = Soportado
Recordar que FT protege ante la falla de hardware del servidor, no fallas de Sistemas Operativos o aplicaciones.
vCenter Server Watchdog es una funcionalidad embebida de la versión 6.x. Periódicamente verifica el estado de los servicios que componen vCenter, reiniciará los procesos de administración o la VM si fuera necesario.


1 Comentarios
Antonio24
mar 08 2016 22:28