HTTrack es una un software libre y gratuito y multiplataforma cuyo fin es la captura web, es decir se descarga todo o parte de un sitio web, para posteriormente poder navegar por él fuera de línea. Existe una versión para Linux se llama WebHTTrack, y su versión para Windows se llama WinHTTrack. Podernos descargar el software HTTrack desde su página oficial:
En caso de Linux también podemos instalarlo desde los repositorios, mediante el siguiente comando.
sudo apt-get install httrack
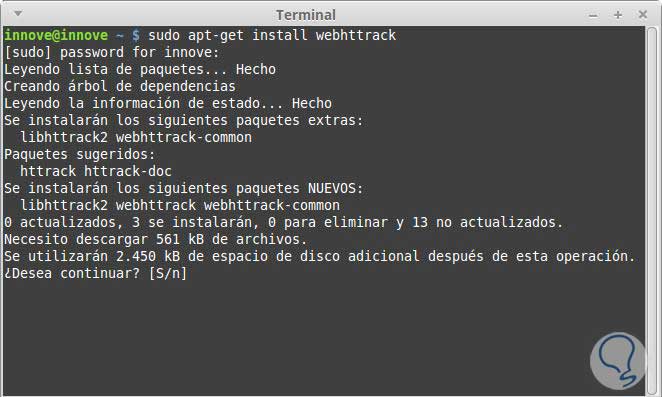
Este software se utiliza mucho para hacer copia de sitios web y luego subirlas a otro servidor y utilizarlas para redirigir tráfico hacia la página copia, enviando visitantes a una página falsa. También lo utilizan quienes desean ver el código o el funcionamiento de una web en particular. Veamos un ejemplo con el sitio web httrack.com, que es donde se aloja la aplicación.
httrack “httrack.com”Este comando descargara los archivos de la web en una carpeta www.httrack.com, que podremos ver en forma local.
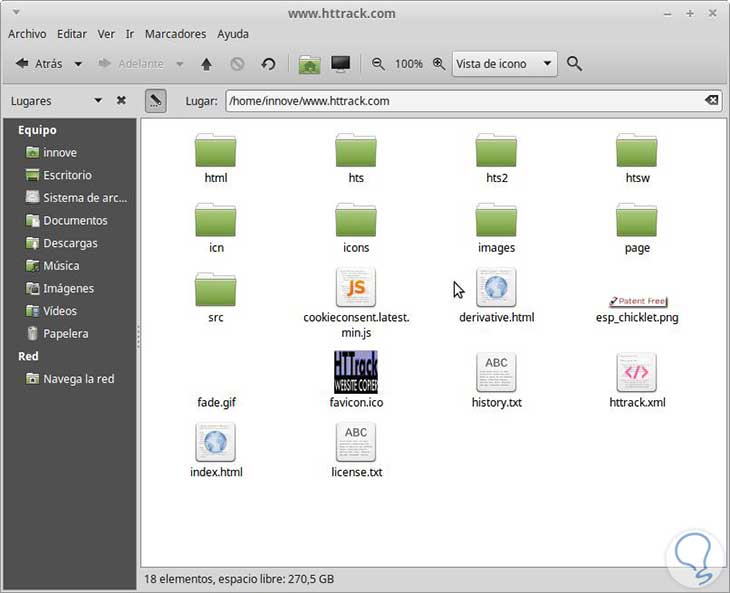
HTTrack toma cualquier sitio web y hace una copia en la carpeta o unidad donde estemos posicionados. Esto puede ser útil para la búsqueda de datos en el sitio web en forma offline, tales como direcciones de correo electrónico, información útil para seo o estructura de una web. HTTrack viene tanto en Windows como en una versión para Linux, y la utilización es la misma solo que en Windows dispone de intergaz visual.
Podemos utilizar Httrack para pruebas de penetración y test de seguridad, ya que al hacer una réplica de un sitio web permite analizar el contenido completo y que archivos se descargan, para determinar que ningún archivo crítico sea visto por un atacante. Cuando recabemos los datos y la información, podemos realizar pruebas, buscar y analizar código o palabras claves, también podemos recolectar datos que podrán ser luego utilizados.
También de esta manera los hackers utilizan las copias realizadas para subirla a un servidor con un dominio similar a la web copiada para emular los sitios web y luego utilizarlos mediante phishing para robar datos a usuarios desprevenidos o para realizar ataques de ingeniería social. Httrack tiene muchas opciones y parámetros para utilizar para mejorar la descarga para ello se utiliza el comando:
httrack --help
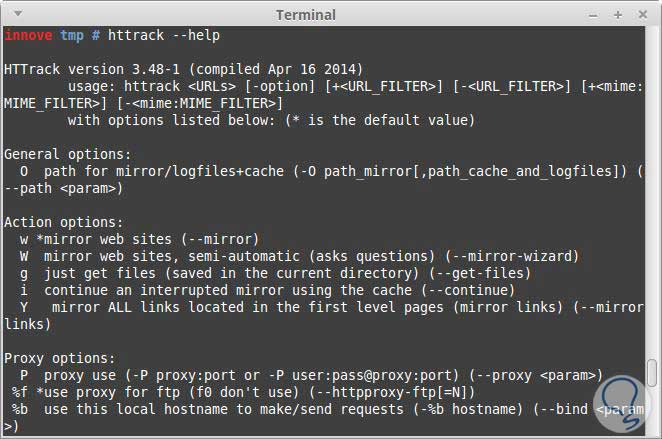
Algunos parámetros importantes que podemos utilizar con la herramienta Httrack son:
- -m: indica el tamaño máximo de archivo en bytes a descargar, por ejemplo -m 20000000 equivalente a 20 mb.
- -mime: sirve para que se descargue solo un tipo determinado de archivo que indicaremos con su extensión por ejemplo con el comando
httrack www.WEB.com -mime:application/* +mime:application/pdfUtilizar httrack es sencillo, debemos añadir el dominio del sitio web que queremos copiar y luego comenzar el escaneo posicionados en un directorio de nuestro disco duro en el que vamos a almacenar el sitio web. Deberemos tener en cuenta que cantidad de enlaces o contenido puede tener una web debido a la cantidad de información a descargar. Explorar la copia de la web puede servir para buscar fallos y vulnerabilidades que pueden poner en riesgo la navegación también para determinar que partes es conveniente cifrar o aumentar la seguridad.
Si el objetivo de la descarga es encontrar información sobre una empresa o listados de usuarios, teléfonos u otros datos en particular para la ingeniería social o tratando de suplantar un sitio web o un login para obtener datos de los usuarios, HTTrack es una excelente herramienta para ambas tareas.
WebHTTrack es una interfaz gráfica para httrack que se utiliza desde un navegador web y permite copias de sitios web completos para acceso sin conexión y modifica los enlaces automáticamente. Herramientas como WebHTTrack pueden ayudar, y permitir la actualización de la copia sin tener que recordar los parámetros para realizar la descarga o copia de una web y de su contenido. Podemos instalarlo con el comando:
sudo apt-get install webhttrackLuego para ejecutarlo escribiremos el mismo comando:
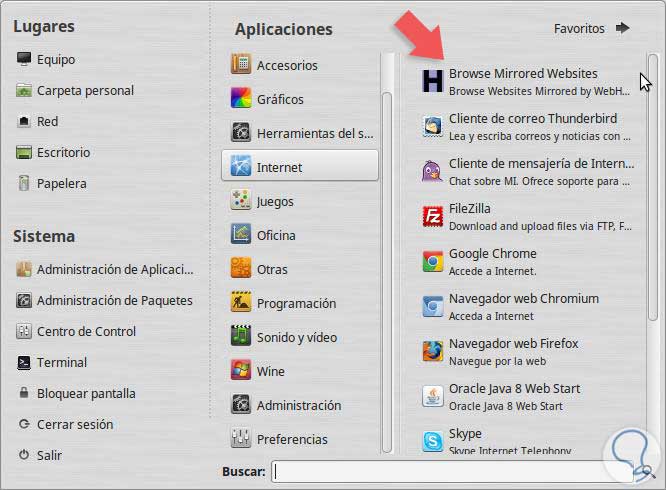
webhttrackPara iniciar la interfaz gráfica, podremos ir al directamente a través del menú de aplicaciones y buscamos la aplicación Browse Mirrored Websites.
Otra opción es simplemente, como dijimos anteriormente desde la ventana de terminal escribir el comando webhttrack para poner en marcha un servidor web local en el puerto 8080, a continuación abrimos el navegador teniendo en cuenta que no esté en modo incógnito o privado y en el navegador escribimos la dirección localhost:8080.

Esto nos mostrara el asistente gráfico que nos ayudara a trabajar con httrack, para comenzar deberemos configurar el idioma y pulsar Siguiente. A continuación configuraremos un Nuevo Proyecto, la ventaja de tener la interfaz gráfica es que podemos guardar en un archivo de texto los datos de los sitios web descargados y los parámetros utilizados.

A continuación asignaremos el sitio web que vamos a copiar:

Luego en Definir opciones configuraremos los parámetros y filtros mediante un asistente:
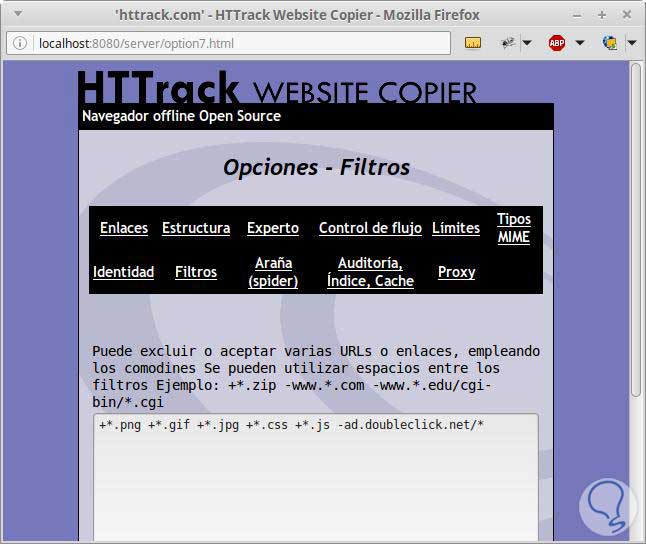
A continuación luego de configurar los filtros, en la próxima pantalla comenzaremos con el escaneo.

- No captura contenido dinámico ni páginas generadas con scripts.
- Si se descargan sitios demasiado grandes o con archivos de gran tamaño se puede colapsar el servidor.
- Si utilizamos httrack en demasiadas conexiones simultáneas a la misma web podríamos ralentizar el servidor o dejarlo fuera de servicio.
Puede ser de tu interés el tutorial dónde se hace un código para rastrear enlaces:



Interesante sistema, lo había oido pero no lo he probado para testing de sites propios.