
A diario estamos descargando, creando y editando diversos tipos de archivos en nuestro sistema operativo, en este caso puntual hablamos de Linux, y uno de los fallos comunes es que frecuentemente podemos contar con diversos archivos duplicados que, no solo ocupan un espacio extra en el disco duro, sino que puede llegar a ser un factor de confusión al momento de abrir y editar archivos.
En muchas ocasiones tenemos en nuestros equipos de escritorio o servidores diversos archivos, independiente del formato que sean, duplicados y no lo sabemos. Esto genera ocupar espacio de manera innecesaria y poder trabajar con un archivo equivocado ya que podemos editar uno y luego abrir el otro, etc. Una forma práctica para llevar una mejor organización de nuestro entorno de trabajo es detectando y eliminado dichos archivos duplicados para que de esta forma sea posible hacer uso de un solo archivo único.
Merece la pena realizar esta tarea no solo para poder borrar los duplicados, sino también para realizar búsquedas donde podamos eliminar y borrar los archivos que no queramos más pero tenemos repetidos por diferentes partes del sistema operativo Linux. Da igual la versión como puede ser en Fedora, Ubuntu, Debian, CentOS entre muchas otras.
Ya vimos en su día cómo encontrar archivos duplicados en Windows, aquí nos centramos en ambientes Linux, donde contamos con herramientas tanto a nivel gráfico como de línea de comandos, que nos ayudarán a encontrar estos archivos y eliminar los que consideremos que no son útiles.

Solvetic explicará la forma para lograr detectar y eliminar archivos duplicados en Linux de una forma sencilla pero funcional.
- Si se encontró A mientras se escaneaba un argumento de entrada anterior a B, A tiene una clasificación más alta.
- Si se encontró A a una profundidad inferior a B, A tiene una clasificación más alta.
- Si se encontró A antes que B, A tiene una clasificación más alta.
- Se crea un bucle sobre cada argumento en la línea de comando, se asigna a cada argumento un número de prioridad, en orden creciente.
- Para cada argumento, se lista el contenido del directorio de forma recursiva y se asigna a la lista de archivos.
- Rdfind asigna un número de profundidad de directorio, comenzando en 0 para cada argumento.
- Si el argumento de entrada es un archivo, este se agregará a la lista de archivos.
- Luego se recorre la lista y se descubren los tamaños de todos los archivos.
- Si el indicador “-removeidentinode” es verdadero se eliminan los elementos de la lista que ya han sido agregados, según la combinación de número de dispositivo y inodo.
- Se ordenan los archivos por tamaño, luego se eliminan los archivos de la lista, que tienen tamaños únicos.
- Se ordena por dispositivo e inodo lo cual acelera la lectura de archivos).
- Se eliminan los archivos de la lista que tengan el mismo tamaño, pero diferentes primeros bytes.
- Se ejecuta la suma de comprobación para cada archivo.
- Solo se conservan los archivos en la lista con el mismo tamaño y suma de comprobación. Estos son los duplicados.
- Se ordenar la lista por tamaño, número de prioridad y profundidad. El primer archivo de cada conjunto de duplicados se considera el original de forma predeterminada.
- Si marca "-makeresultsfile true", se imprime el archivo de resultados (predeterminado).
- Si el indicador es "-deleteduplicates true", se eliminarán los archivos duplicados.
- Si el indicador es "-makesymlinks true", se procede a reemplazar los duplicados con un enlace simbólico al original.
- Si el resultado es "-makehardlinks true", se procede a reemplazar los duplicados con enlace al original.
1. Buscar archivos duplicados con la utilidad Rdfind en Linux
Para instalar Rdfind en Linux podemos ejecutar alguno de los siguientes comandos:
sudo apt install rdfind (Debian/Ubuntu/Mint) sudo yum install epel-release && $ sudo yum install rdfind (CentOS/RHEL) sudo dnf install rdfind (Fedora)
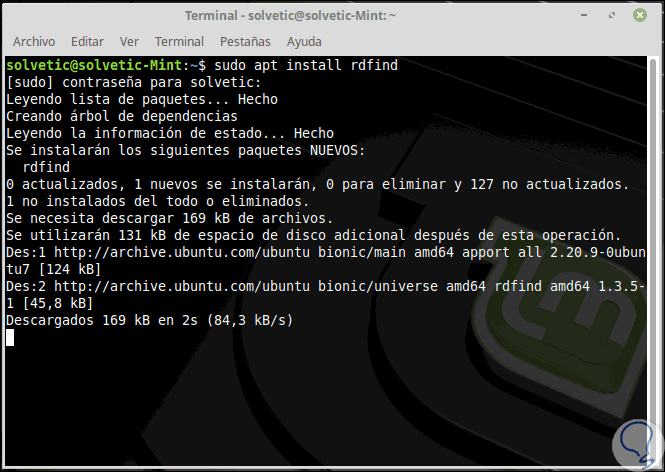
Una vez descargado e instalado Rdfind, vamos a ejecutarlo en un directorio simple de la siguiente manera:
rdfind /home/Solvetic
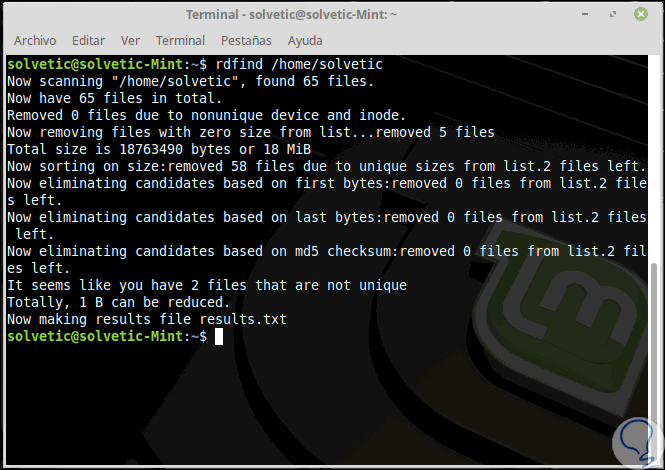
Allí podemos ver que se detecta la cantidad de archivos en dicho directorio y se indica si han sido eliminados o no archivos duplicados. La utilidad Rdfind guardará los resultados en un archivo results.txt ubicado en el mismo directorio desde donde ejecutó el programa, podremos ver su contenido usando cat:
cat results.txt
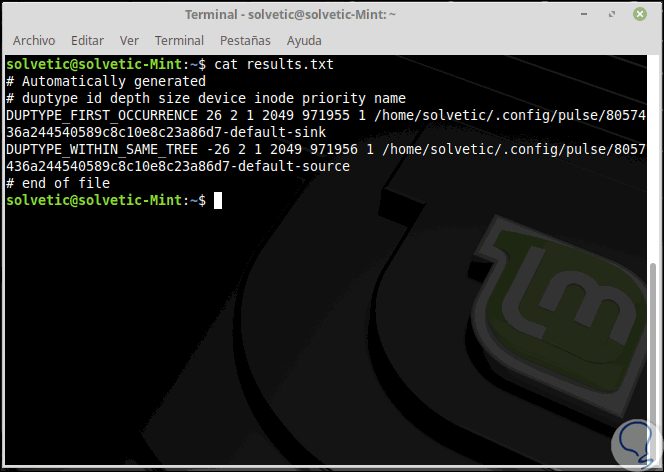
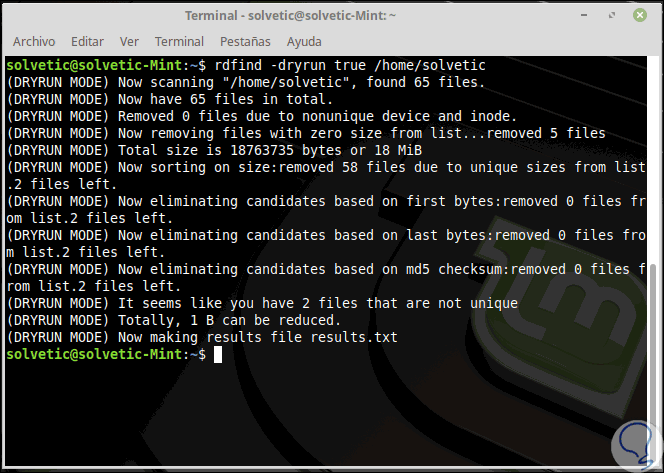
Una tarea extra para usar con rdfind es usar el parámetro "-dryrun" el cual proporcionará una lista de duplicados sin realizar ninguna acción sobre ellos:
rdfind -dryrun true /home/Solvetic
En caso de detectar duplicados, es posible reemplazarlos con hardlinks así.
rdfind -makehardlinks true /home/user
Para eliminar los duplicados debemos ejecutar lo siguiente:
rdfind -deleteduplicates true /home/user
para acceder a la ayuda de Rdfind usaremos el siguiente comando:
man rdfind
2. Buscar archivos duplicados con la utilidad Fdupes en Linux
Otra de las opciones que tenemos en Linux para validar aquellos archivos duplicados es Fdupes. Es una herramienta de línea de comandos que nos permite observar detalladamente que archivos tenemos duplicados en el sistema. Fdupes es un programa que ha sido desarrollado para identificar o eliminar archivos duplicados alojados dentro de directorios específicos en Linux, es de código abierto y gratuito y está escrito en C.
- Comparando firmas md5sum parciales.
- Comparando todas las firmas de md5sum.
- Verificación de comparación byte a byte.
Al usar Fdupes tendremos opciones de uso como:
- Búsqueda recursiva.
- Excluir archivos vacíos.
- Desplegar el tamaño de los archivos duplicados.
- Eliminar duplicados inmediatamente.
- Excluir archivos con diferente propietario.
Por defecto esta herramienta no se encuentra instalada por lo cual debemos ingresar el siguiente comando para su instalación. Para instalar Fdupes ejecutaremos el siguiente comando:
sudo apt install fdupes
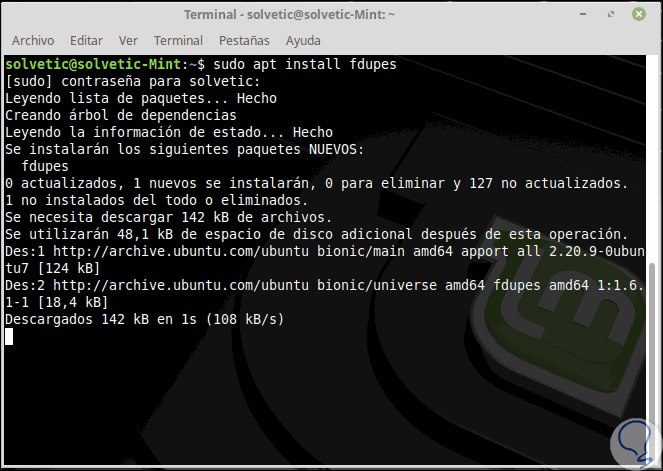
Una vez descargado, podremos ejecutar la siguiente línea para una búsqueda simple. Allí se desplegarán los archivos duplicados.
fdupes /ruta a buscar
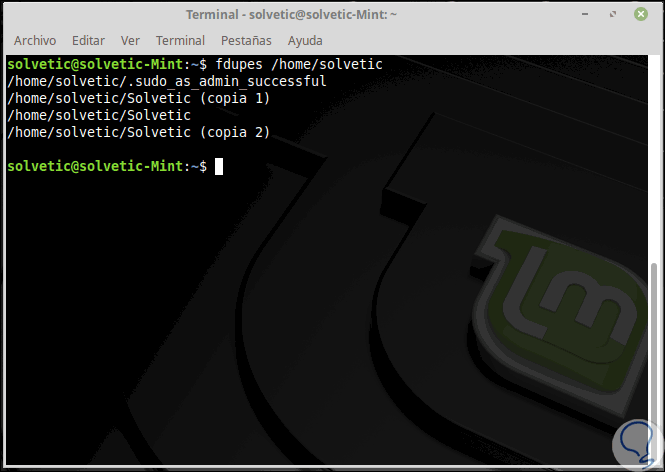
Para ejecutar una búsqueda recursiva usaremos la siguiente línea:
fdupes -r /ruta a buscar
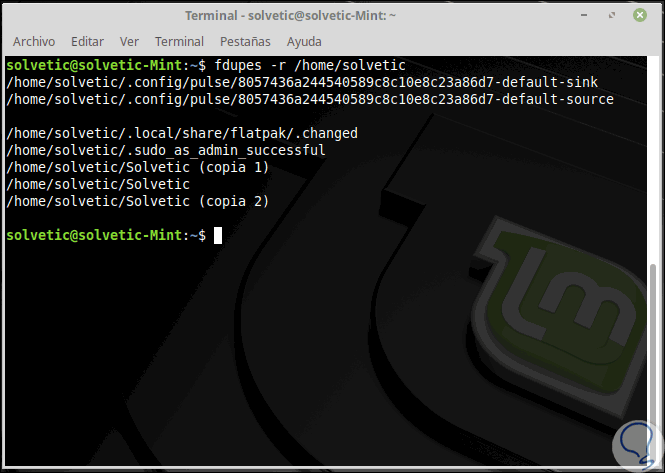
Será posible especificar varios directorios y especificar un directorio para buscar recursivamente de la siguiente forma:
fdupes <dir1> -r <dir2>
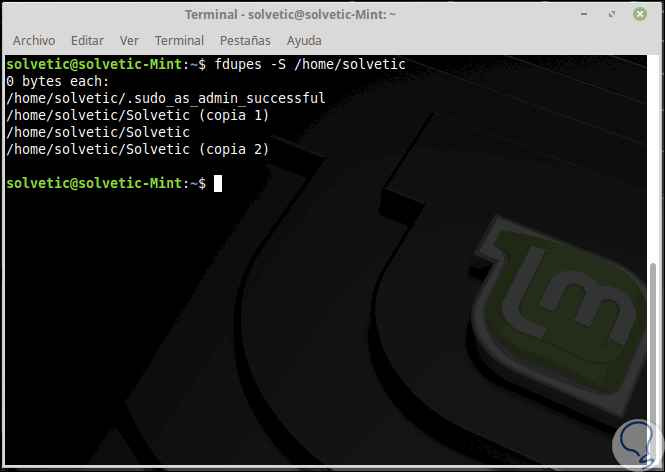
Si deseamos que Fdupes calcule el tamaño de los archivos duplicados, usaremos la opción -S:
fdupes -S <dir>
Para recopilar información resumida sobre los archivos encontrados usaremos la opción -m:
fdupes -m <dir>
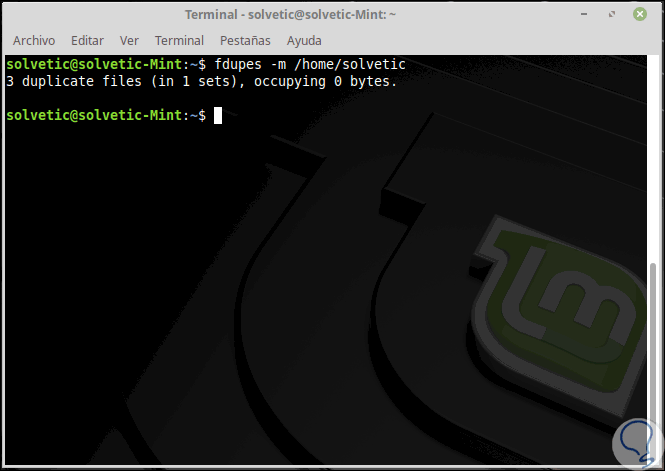
En caso de desear borrar todos los duplicados ejecutaremos lo siguiente:
fdupes -d <dir>
Si deseamos acceder a la ayuda de la utilidad ejecutamos:
fdupes -help
Algunas de las opciones de uso generales son:
-r –recurse
-R --recurse
-s –symlinks
-H –hardlinks
-n –noempty
-A –nohidden
-S –size
-d –delete
-q –quiet
-o --*****=BY
-l --log=LOGFILE
-v –version
-h – help
3. Buscar archivos duplicados con la utilidad FSlint en Linux
Otra que vamos a utilizar es FSlint, la cual viene por defecto en las diversas ditros de Linux tales como Ubuntu, Debian, Fedora, etc. Para saber más acerca de FSlint podemos visitar el siguiente enlace:
Podemos buscar FSlint desde el menú Actividades para su uso.
Una vez abierto es necesario que instalemos la aplicación, para ello basta con pulsar en el botón Install e iniciará el proceso de instalación de la utilidad.
Una vez la herramienta ha sido instalada procedemos a su ejecución y veremos el siguiente entorno:
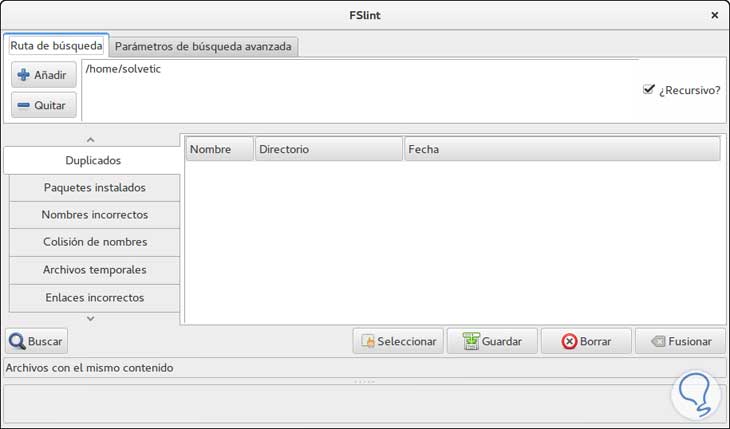
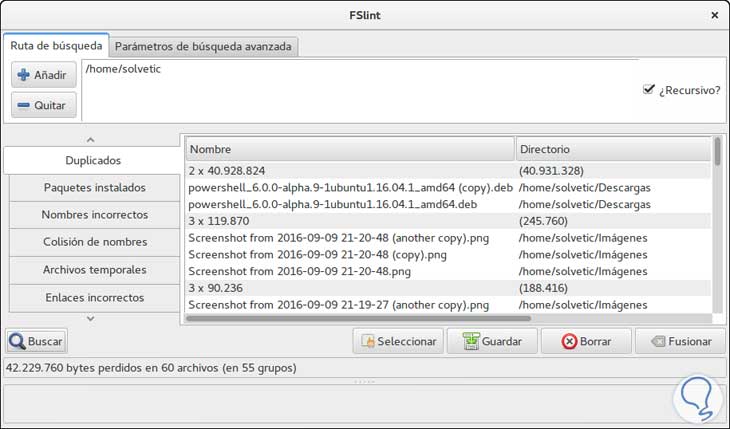
Para iniciar el proceso de búsqueda de todos los archivos duplicados pulsaremos el botón “Buscar” ubicado en la parte inferior y el resultado será similar a este. Allí podremos seleccionar aquellos archivos que no son necesario y eliminarlos pulsando el botón Borrar. La herramienta FSlint también puede ser usada desde la terminal en Ubuntu 16.
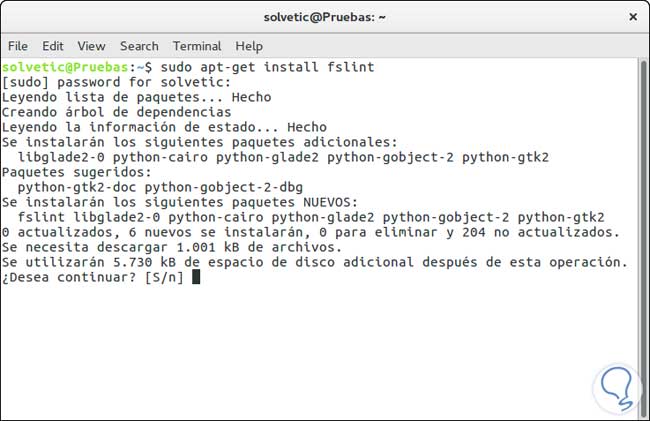
Si deseamos instalar la herramienta desde la terminal ingresaremos el comando:
sudo apt-get install fslint
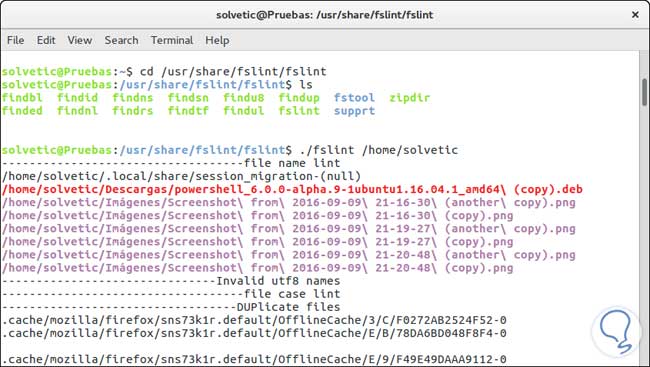
Una vez esté instalado FSlint ingresaremos los siguientes comandos para usar FSlint. Podemos ver que se despliegan todos los archivos que tenemos duplicados en el Sistema.
cd /usr/share/fslint/fslint (Esta es la ruta por defecto en Ubuntu) ./fslint /Ruta a buscar archivos
Podemos ver que contamos con dos opciones prácticas para detectar y eliminar archivos duplicados en ambientes Linux y así administrar mejor el espacio y los archivos a usar.





Gracias!!!