El Screen Scraping o raspado de pantalla, nos permite extraer de una página web información mediante la descarga de dicha página y su posterior procesamiento con algún programa; esto es muy útil sobre todo cuando necesitamos información actualizada de alguna web que no tiene ningún API disponible o algún Web Service.
Para llevar a cabo un Screen Scraping, simplemente debemos bajar el contenido y poder manipularlo de forma que podamos extraer lo que nos interesa, para ello podemos valernos de varias técnicas como el uso de expresiones regulares o tal vez ayudarnos con otras librerías como Tidy.
¿Qué es Tidy?
Para poder leer un HTML debemos confiar en su estructura, esto debido a que como no sabemos exactamente que contenido tiene, al menos sabemos que si buscamos por estructuras HTML algo podemos obtener, sin embargo, no siempre el HTML está bien formado, ya sea por un error de omisión, o porque el programador sabe que algunos navegadores tienden a interpretar el HTML así hayan algunas fallas.
En este punto entra en juego Tidy, que no es más que una herramienta que nos permite reparar el HTML mal formado, es altamente configurable y nos permite personalizar la forma en que debe interpretar las correcciones que pueda hacer, de esta manera sabremos con certeza qué tipo de documento nos resultará al final.
Veamos primero una imagen de un código HTML con muchos errores, este código puede ser interpretado por algunos navegadores, sin embargo no es un código correcto en su formación:
Como podemos notar, cada línea prácticamente tiene un error, el más común es el no cierre de etiquetas, luego vemos etiquetas que cierran en el lugar incorrecto, etc.
Luego que utilizamos Tidy y veamos el código ya corregido, ahí nos daremos cuenta de lo importante de esta librería y toda la ayuda que nos puede prestar:
En la imagen vemos como fue corregido por Tidy, debemos acotar que aunque Tidy es una gran librería probablemente no pueda resolver todos los errores de HTML, sin embargo nos ayuda bastante a la hora de construir nuestro HTML bien formado.
Obtener Tidy
Existen varias formas de obtener Tidy a través de su página oficial http:/ /tidy.sf.net. podemos obtener la librería, sin embargo no existe en esa fuente una forma de integrarlo con Python por lo que debemos recurrir a una fuente alternativa, para ello tenemos dos opciones: uTidy disponible en http:/ /utidylib.berlios.de y mxTidy disponible en http:/ /egenix.com/files/python/mxTidy.html, uTidy pareciera ser el más actualizado de ambos pero mxTidy es un poco más sencillo de instalar, queda de parte de cada quien ver cual utilizar.
Veamos un ejemplo de cómo utilizar Tidy una vez que lo tenemos instalado, en el siguiente código lo que haremos es abrir un HTML con errores y leerlo utilizando Tidy, luego mostraremos la información por pantalla.
Como vemos es bastante sencillo la utilización de Tidy, una vez que ya le tenemos la confianza suficiente al conocer bien el comportamiento de la librería, podremos lograr cosas muy interesantes.
Para llevar a cabo un Screen Scraping, simplemente debemos bajar el contenido y poder manipularlo de forma que podamos extraer lo que nos interesa, para ello podemos valernos de varias técnicas como el uso de expresiones regulares o tal vez ayudarnos con otras librerías como Tidy.
¿Qué es Tidy?
Para poder leer un HTML debemos confiar en su estructura, esto debido a que como no sabemos exactamente que contenido tiene, al menos sabemos que si buscamos por estructuras HTML algo podemos obtener, sin embargo, no siempre el HTML está bien formado, ya sea por un error de omisión, o porque el programador sabe que algunos navegadores tienden a interpretar el HTML así hayan algunas fallas.
En este punto entra en juego Tidy, que no es más que una herramienta que nos permite reparar el HTML mal formado, es altamente configurable y nos permite personalizar la forma en que debe interpretar las correcciones que pueda hacer, de esta manera sabremos con certeza qué tipo de documento nos resultará al final.
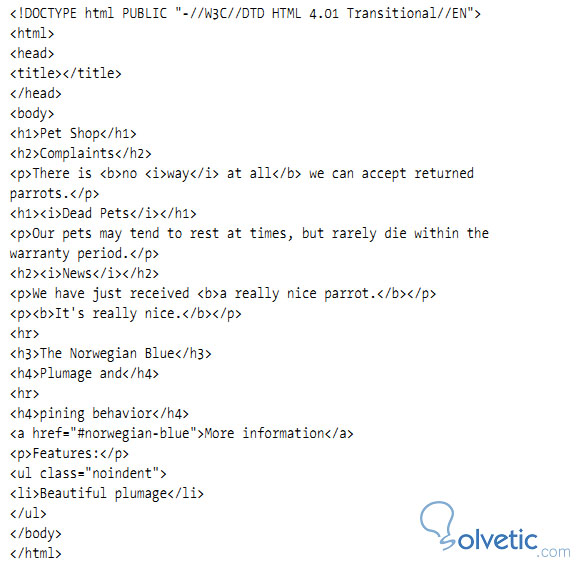
Veamos primero una imagen de un código HTML con muchos errores, este código puede ser interpretado por algunos navegadores, sin embargo no es un código correcto en su formación:

Como podemos notar, cada línea prácticamente tiene un error, el más común es el no cierre de etiquetas, luego vemos etiquetas que cierran en el lugar incorrecto, etc.
Luego que utilizamos Tidy y veamos el código ya corregido, ahí nos daremos cuenta de lo importante de esta librería y toda la ayuda que nos puede prestar:
En la imagen vemos como fue corregido por Tidy, debemos acotar que aunque Tidy es una gran librería probablemente no pueda resolver todos los errores de HTML, sin embargo nos ayuda bastante a la hora de construir nuestro HTML bien formado.
Obtener Tidy
Existen varias formas de obtener Tidy a través de su página oficial http:/ /tidy.sf.net. podemos obtener la librería, sin embargo no existe en esa fuente una forma de integrarlo con Python por lo que debemos recurrir a una fuente alternativa, para ello tenemos dos opciones: uTidy disponible en http:/ /utidylib.berlios.de y mxTidy disponible en http:/ /egenix.com/files/python/mxTidy.html, uTidy pareciera ser el más actualizado de ambos pero mxTidy es un poco más sencillo de instalar, queda de parte de cada quien ver cual utilizar.
Veamos un ejemplo de cómo utilizar Tidy una vez que lo tenemos instalado, en el siguiente código lo que haremos es abrir un HTML con errores y leerlo utilizando Tidy, luego mostraremos la información por pantalla.
from subprocess import Popen, PIPE
text = open('messy.html').read()
tidy = Popen('tidy', stdin=PIPE, stdout=PIPE, stderr=PIPE)
tidy.stdin.write(text)
tidy.stdin.close()
print tidy.stdout.read()
Como vemos es bastante sencillo la utilización de Tidy, una vez que ya le tenemos la confianza suficiente al conocer bien el comportamiento de la librería, podremos lograr cosas muy interesantes.

